Caching Data Access Strategies — Ecstasy & Agony
Cache is pronounced “CASH” is one of the easiest and proven techniques to increase system performance and scalability. Databases are slow (even the No SQL). As mantra says “Speed is the name of the game”.
It does temporarily copying frequently accessed data to fast storage that’s located close to the application. The data in a cache is generally stored in fast access hardware such as RAM (Random-access memory) and may also be used in correlation with a software component.
Trading off capacity for speed, a cache typically stores a subset of data transiently, in contrast to databases whose data is usually complete and durable.
In this post, let’s begin with the server-side caching strategy with their ecstasy and agony. We will speak about client-side caching in the later posts.
If caches are done right, it can reduce response times, decrease the load on the database, and save costs. There are several ways and choosing the right one can make a big difference. It all depends on the data and data access patterns. Let’s ask our self some questions to decide on the caching strategy:
- Is the system write-heavy and reads less frequently?
- Is data written once and read multiple times?
- is data returned always unique?
- What are the use cases in the system that require high throughput, fast response, or low latency?
- Does data inconsistency be compromised on the use of cache?
- What kind of data needs to store? key-value pairs, static data, objects, or in-memory data structures?
- Do you need to maintain the cache for transactional/master data?
- Do you need an in-process cache or shared cache in a single node or distributed cache for n number of nodes?
- What is the expectation on performance, reliability, scalability, and availability while use distributed cache?
Caching Benefits
Caching benefits both the producers and consumers. Below are the benefits that bring to content delivery:
- Decreased Network costs
- Improved Responsiveness
- Increased Performance on the same infrastructure
- Availability of the data during network interruptions
Caching Data Access Strategies
Cache-Aside
This is the most commonly used caching approach. The cache sits on the side and the application directly talks to both the cache and database. The application first checks the cache and data found in the cache, we’ve cache-hit. If not found, we’ve cache-miss. The data is retrieved from the database and respond to request and update the cache.

- Cache-aside caches usually work best for read-heavy workloads. Memcached and Redis are widely used.
- Systems using these patterns are resilient to cache failures. If the cache cluster goes down, the system can operate directly retrieving from the database.
- The data structure of the cache can be different than the data structure in the database.
Read Through / Lazy Loading
Load the data into the cache only when it is necessary. If the system needs data for the key, find it in the cache, if present, return the data. else, retrieve from the data store and put it into cache and then return.

Pros:
- It’s on-demand and does not load all the data in the cache without need.
- Suitable for applications/systems that do need not load all the data from the data store.
- If there are multiple cache instance nodes and an instance fails, it does not fail the application, it increases latency and a new cache instance node comes up and builds the cache with every cache miss.
Cons:
- For the cache miss, there is a check in the cache, retrieve from the data store, put it in a cache. So a noticeable delay in the response — 3 network operations.
- Stale data might become an issue. If data changes in the data store. It may get stale data if the cache key is not expired.
Write Through
While Upsert data in the datastore, upsert the data in the cache as well. So both of the actions have to be in a single transaction(atomic) otherwise data staleness will be there.
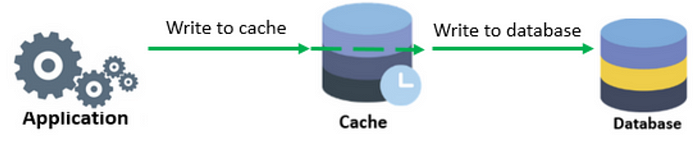
Pros:
- No Stale data. It addresses the staleness issue in the Read Through approach
- Suitable for read-heavy systems which can’t have staleness
Cons:
- For Every Write operation, it writes data to the data store and then writes to cache — 2 network operations.
- If the data in the cache is not read, it becomes unnecessary to hold data called Cache churn. This can be controlled by using TTL or expiry.
- Consistency needs to be maintained between cache and data store. On writing, one fails, fail the other as well.
Write Behind / Write Back
The application writes data directly to the cache and asynchronously sync the data with the data store. The order of sequence needs to be maintained in the queue of writes on cache and datastore.
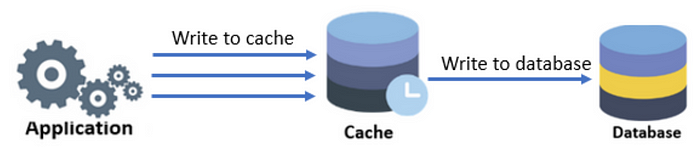
Pros:
- It improves performance as the data is read and write on the cache directly. It does not need to wait till data is written to the data store.
- More resilience — The application is protected from datastore failure. If it fails, the queued data can be retried or re-queued.
Cons:
- Eventual consistency to be maintained between the datastore and caching system. Any direct operation on the datastore may cause stale data
Refresh Ahead Caching
It’s a technique in which the cached data is refreshed before it expired. This technique is used in Oracle coherence.
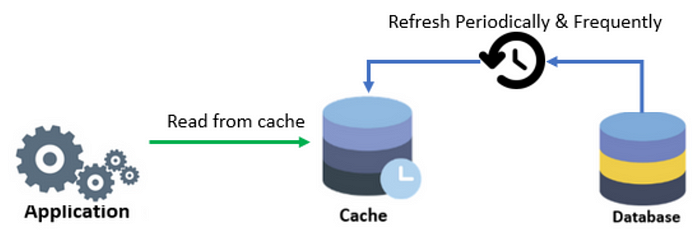
Pros:
- It’s useful when a large number of requests/processing using the same cache keys.
- Since the data is refreshed periodically and frequently, staleness data is avoided.
- Reduced latency than other techniques
Cons:
Little hard to implement since the service takes additional resources to refresh all the keys as and when they are accessed. Suited for a read-heavy environment.
Eviction Policy
An Eviction policy enables a cache to ensure that the size of the cache doesn’t exceed the maximum limit. A caching solution provides different eviction policies such as :
- Least Recently Used (LRU)
- Least Frequently Used (LFU)
- Most Recently Used (MRU)
- First In, First Out (FIFO)
Let’s see more details about these eviction policies in detail in the next coming blogs.
Summary
In this post, we explored different caching strategy and their pros and cons. We need to evaluate the goals, data access pattern (read/write) an choose the right caching strategy and eviction policy. In the real world, high throughput systems, when memory is never big enough and server costs are a concern, the right strategy matter. Enjoy the ecstasies and absorb the agony.
I hope you got something out of this blog. If you found this post illuminating at all, consider sharing this post and following for more upcoming content.
